
机器之心剪辑部
鄙人载量遏止 1.5 亿次之际,谷歌 Gemma 4 系列模子迎来了新的眷属成员!
今天,谷歌认真推出 Gemma 4 12B,成见是把具备智能体材干的多模态智能,胜仗带到条记本电脑上。
凭证先容,Gemma 4 12B 介于面向边际成立的 E4B 与材干更强的 26B 羼杂大家模子(MoE)之间,在更小的内存占用下提供了庞大的材干。
另外,Gemma 4 12B 亦然谷歌首个支撑原生音频输入的中等规模模子。
谷歌 DeepMind 创举东谈主兼 CEO 哈萨比斯,「为庆祝 Gemma 4 下载量遏止 1.5 亿次这一关键里程碑,谷歌发布了全新的 Gemma 4 12B 模子!关于这么一个小尺寸模子来说,它的材干特殊庞大;同期,它也迷漫轻量,只需 16GB 显存,就能在条记本电脑上腹地运转。」
全球不错用它构建了多样各种的行使,从用于物理扶助的可衣裳机器东谈主手臂,到企业级 AI 安全系统。谷歌也期待看到开辟者用这款最新模子创造出更多可能。
这次,Gemma 4 12B 模子具有以下几大特质:
全新的和洽架构:不再使用多模态编码器,视觉和音频输入不错胜仗参预 LLM 骨干收罗。
更强的推理材干:在基准测试中的证实接近谷歌的 26B 模子,大约支撑庞大的多步推理和智能体职责流。
相宜条记本腹地运转:模子规模迷漫小,只需要 16GB 显存或和洽内存即可在腹地运转。
通达且易于得回:接纳 Apache 2.0 许可证发布,并支撑无为的开辟者生态。
支撑草稿模子加快:Gemma 4 12B 配备了多 Token 忖度(MTP)草稿模子,可用于裁减延伸。
现在,用户不错通过 LM Studio、Ollama、Google AI Edge Gallery App、Google AI Edge Eloquent App 以及 LiteRT-LM CLI 等渠谈进行试用。
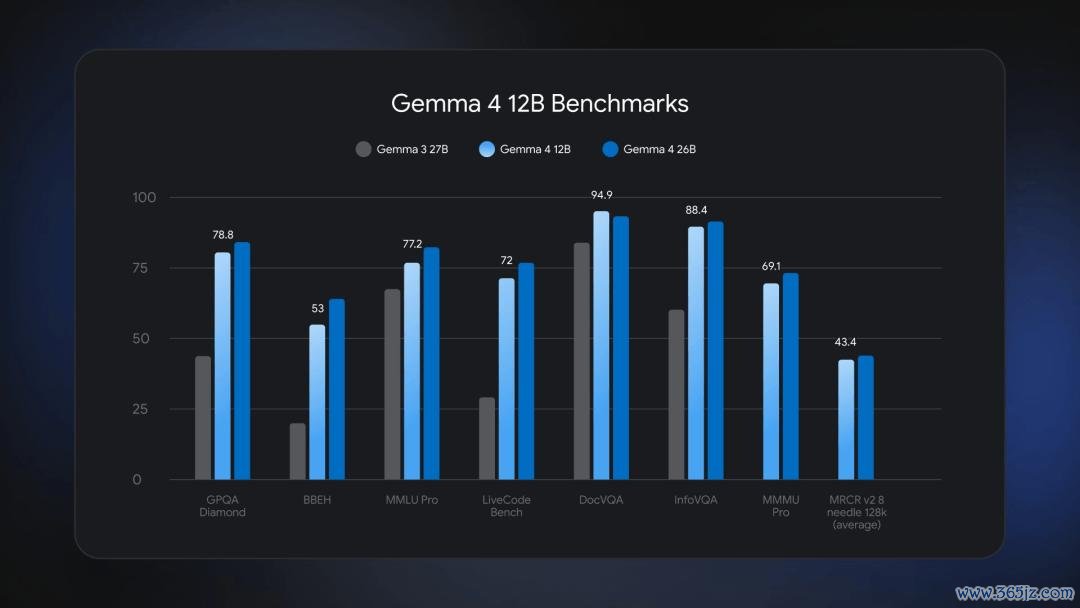
在 GPQA Diamond、BBEH、MMLU Pro、LiveCode Bench、DocVQA、InfoVQA、MMMU Pro 和 MRC v2.8 needle 128k(average)等一系列基准测试中,Gemma 4 12B 的证实接近谷歌更大的 26B MoE 模子,但全体内存占用不到后者的一半。
况且,它的规模迷漫小,ag·真人(官网)平台不错在配备 16GB 内存的亏蚀级条记本电脑上腹地运转,从而把庞大的多模态体验和智能体材干带到你的个东谈主成立上。
有东谈主在一张 RTX 4090 上腹地运转了 Gemma 4 12B 和 Gemma 4 26B-A4B,并给它们交接了归拢个任务:在不使用任何库的情况下,用单个文献写出一个自包含的 HTML5 Canvas 动画,并加入果然物理成果。测试包含三个场景:高尔顿板、两个方块与墙面碰撞,以及婉曲三重摆。输出戒指如下:
Gemma 4 26B-A4B:占用 15GB 显存,生成 6.9k tokens,速率 138 tokens/s
Gemma 4 12B:占用 9GB 显存,生成 8.9k tokens,速率 80 tokens/s
同属 Gemma 4 眷属,但 26B-A4B 在三个场景中都胜出,而且运转速率快了约 1.7 倍,它的活跃参数目只须 4B。不外,12B 的证实也特殊接近,同期显存占用险些只须一半。这也让它成为 16GB 条记本上的理念念腹地模子。


另外,Gemma 4 12B 最特出的地点在于,它责罚视觉和音频输入的面容愈加精简。
传统多模态模子每每依赖独处编码器,先把图像和音频调养成模子可理解的暗示,再传递给说话模子。但这些永诀式编码器会带来特别延伸,也会增多内存占用。因此,谷歌在训练 Gemma 4 12B 时接纳了无编码器架构,让音频和视觉输入大约胜仗整合进模子。
Gemma 4 12B 原生责罚多模态输入的面容如下:
视觉:谷歌用一个轻量级镶嵌模块替代了 Gemma 4 的视觉编码器。这个模块由一次矩阵乘法、位置镶嵌和归一化构成,让 LLM 骨干收罗接纳视觉责罚。
音频:音频责罚进一步简化。谷歌皆备移除了音频编码器,并将原始音频信号投影到与文本 token 疏通的维度空间中。
在 Google AI Edge Eloquent App 中,Gemma 4 12B 不错皆备离线完谚语音输入的转录、规范整理和翻译。
 APP STORE
APP STORE